Ecrit le 29 juin 2021

Mal compris, le test de charge est au mieux la dernière roue du carrosse dans la conduite d’un nouveau projet et au pire complètement oublié au profit des urgences de production.
La plupart des acteurs limitent le test de charge à un simple stress test, hors un test de charge permet de mettre en avant des éléments qui ne seraient pas visibles par ailleurs.
Voici un exemple de contention que seul un test de charge peut révéler : la saturation du réseau backend.
Dans notre retour sur expérience, l’architecture testée est composée de trois frontaux et de deux serveurs backend. Les serveurs backend fournissent un service MySQL master/slave, c'est-à-dire qu’il n’y a qu’un serveur actif à la fois et un service de cache Redis qui fonctionne également en master/slave.
Sur les 2 backends, le premier est master pour MySQL et slave pour Redis, le second est slave pour MySQL et master pour Redis. Ainsi, les flux réseaux provenant des frontaux sont distribués sur les 2 backends.
Le test de charge a été effectué avec JMeter et le nombre de threads augmente de 25 toutes les 10 minutes :
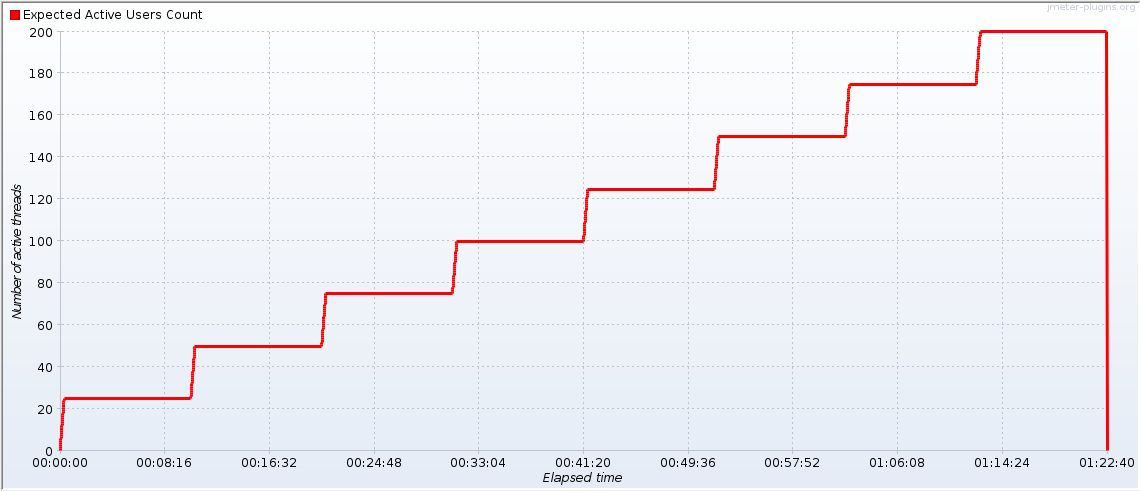
Nombre de threads JMeter en fonction du temps
L’utilisation des paliers permet de voir la correspondance avec les métriques côté serveurs. Si tout était idéal, on retrouverait un escalier avec des paliers de 10 minutes sur les graphes des serveurs.
Voici la consommation CPU d’un frontal qu’on peut superposer à la courbe de JMeter tout du moins au début. On voit que les CPU démarrent par des marches d’escalier, mais au bout du troisième palier, après 30 minutes, la CPU ne suit plus les marches !
C’est typique d’une contention qui apparaît au-delà au troisième palier, donc entre 50 et 75 threads au niveau de JMeter.
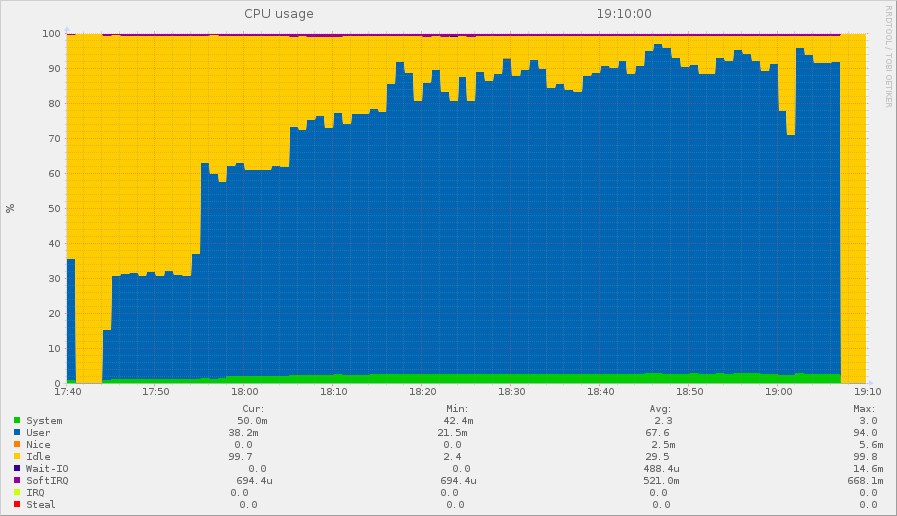
Utilisation de la CPU d'un frontal
"load average" d’un frontal
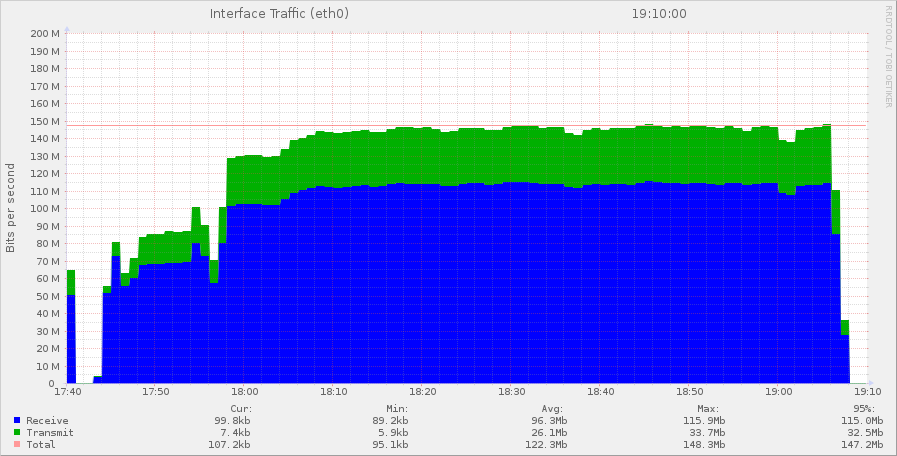
Trafic réseau d’un frontal en mega bits/seconde
On voit que les frontaux reçoivent beaucoup plus de données qu’ils n’en délivrent. Dans la partie verte se trouvent les réponses, c'est-à-dire les pages émises vers les navigateurs et les requêtes faites sur la base de données MySQL et Redis. En bleu, on trouve les requêtes des navigateurs reçues par les frontaux, mais surtout les réponses des backends.
Que se passe-t-il du côté des backends ?
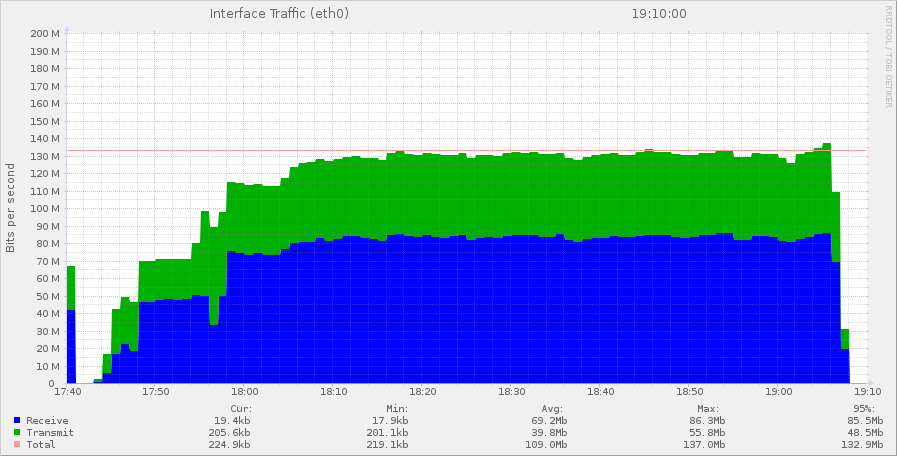
Trafic réseau du serveur MySQL master
Le serveur MySQL reçoit plus de trafic qu’il n’en délivre ! C’est probablement la réplication Redis qui est la source de ce trafic entrant.
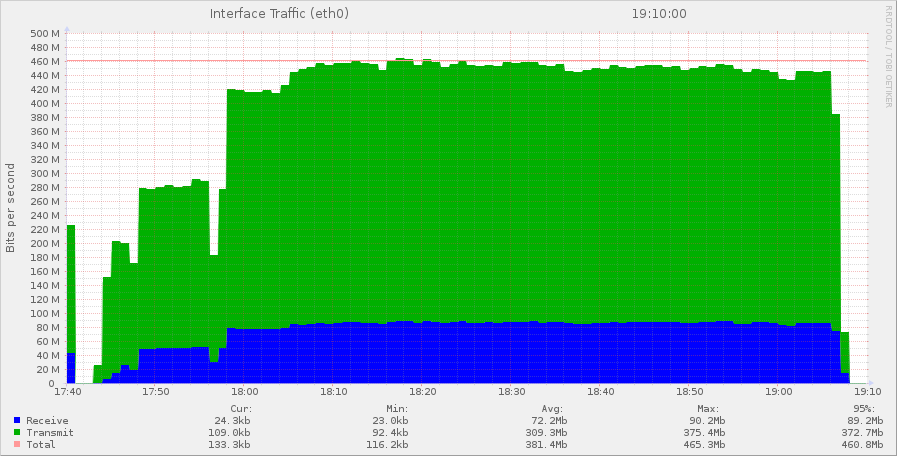
Trafic du serveur Redis master
Le serveur Redis émet énormément de trafic vers l’extérieur.
Dans ce trafic émis, il y a la réplication Redis pour une part mais aussi les informations qui permettent à l’application de créer les pages.
Et surtout on note l'écrêtage du débit au troisième palier avec un flux de 450 Mbps !
Pourquoi atteint-on une limite à 450 Mbps alors qu’en théorie on devrait passer du 1000 Mbps ?
Parce qu’en pratique, il y a 4 machines qui conversent avec ce serveur, et elles font énormément de requêtes. Donc on se trouve loin des conditions optimales de débit.
On voit dans le graphes des frontaux que le trafic émis est de l’ordre de 30 Mbps. Donc le site a un débit de moins de 100 Mbps. Alors que le trafic émis par Redis dépasse les 375 Mbps. Il faut trois fois plus d’informations pour construire une page que ce qu’elle ne contient !
On constate pour cette application une sur-utilisation de Redis. Rien d’étonnant, puisque le Redis stocke les données prêtes à être exploitées par l’application. Les résultats sont pré machés dans Redis et renvoyés directement depuis la mémoire, ce qui accroît les performances. En un peu plus d’une dizaine d’années, le codage des applications passe de l’exécution de requêtes SQL à la lecture des données dans Redis.
En fait on utilise Redis comme de la RAM, c'est-à-dire de la mémoire locale. Sauf que quand on a plusieurs frontaux, cette mémoire est partagée. Le bon côté c’est que ça évite de charger des données en cache pour chaque frontal. Le mauvais côté, c’est qu’on accède à cette mémoire à travers le réseau, qui n’a pas du tout les mêmes performances que la RAM.
A noter qu’au bout du troisième palier on sature le réseau, il était donc inutile de faire 8 paliers pendant 1h30 lors de ce test de charge !
Ce type de contention réseau au niveau des backends est assez courante sur les grosses infrastructures qui multiplient les frontaux et les VM ou services.
Les perspectives d’amélioration passent par une modification d’architecture, comme utiliser le Redis avec une réplication master/master ou des lectures sur le slave pour alléger le master. Mais surtout, l’application n’est certainement pas optimisée puisqu'elle nécessite pour pour produire ses pages, la lecture de 3 fois plus de données. Il y a donc très certainement un gâchis de lecture de tableaux dont on ne conserve que quelques informations…
La démarche de préservation des ressources prend toute son importance sur les sites à forte audience !